C++11-14新标准
😄C++11-14新标准
记录C++11&14中出现的新特性,主要分为语言和标准库两部分
语言
介绍C++11中新出现的语言特性
Variadic Templates
总结来说就是可以接收变长参数,在标准库中的万用哈希函数hash_val以及tuple等知识都用到了Variadic Templates这个新特性,接收变长参数,将其一层一层的处理
举一个简单的例子:

函数print接收的参数个数不定,假设传递n个参数,print将n个参数分成1和n-1个,先输出一个
然后在函数体内调用自身,传递n-1个参数,print将n-1个参数分成1和n-2个,输出一个。。。
就这样一层一层的调用自身,每次调用之前先减少一个参数
最后一层剩下一个参数,调用自身传递0个参数,到了结束标志,整个打印结束
递归调用自身,调用过程中剥离参数进行处理,使得参数变得越来越少
总结一个变长参数的函数模板:
| |
如果想要知道后面的n-1个参数的大小,可以使用sizeof...(otherArgs)
...是一个包,出现在不同参数的后面就是不同的包:
typename...,模板参数包Types... otherArgs,函数参数类型包otherArgs...,函数参数包
不仅仅是函数,tuple也借用了变长参数的理论来实现自身,tuple可以存放不同的元素,在调用构造函数时,将传递进来的参数分成1和n-1,然后剩下的n-1以继承的方式交给新的tuple
最后使用一个空tuple处理边界条件
获取tuple中的元素时,使用head和tail,head返回1,tail返回n-1形成的tuple,在代码中先返回this,再对this进行转型
具体的实现细节如图所示:

函数和类的处理思路是一样的,一个是调用自身,一个是继承自身,在这个过程中减少参数量
hash_val的处理方式也是这样,对于自定义类型的哈希,将自定义类型拆分成多个系统内置类型,之后使用hash_val将这些拆分类型传递过去进行处理
由于不同自定义类型使用的系统内置类型的个数不定,所以使用了variadic templates的思想接收变长参数,可以实现万用性
测试例子
一共有三个地方需要使用...
- typaname… Types
- const Types&… otherAgrs
- otherArgs…
| |
容器嵌套容器
最开始c++容器嵌套容器时,需要使用空格区分是容器还是输出运算符,但是c++11新标准之后,编译器已经可以智能的区分了,所以不用加空格
| |
auto
编译器可以自动推导变量的类型,和模板或者函数重载一样,可以自动推导出参数的类型
| |
当参数的类型名很长,例如迭代器,或者参数的类型实在想不起来的时候,就可以使用auto,但是不推荐任何地方都是用auto,这样会降低代码的可读性
统一初始化
c++11之前对于初始化的操作有多种不统一的方式,()、{}、=都可以用来初始化,并且每个变量支持初始化的方式不同,这就导致了初始化时会造成一些不必要的错误
基于这个原因,c++11提出了一个统一初始化,规定任何变量都可以使用{}初始化,当然以前的方式都保留,只是给一些没有{}赋值的变量增加了这种方式
不知道怎么初始化就用{}
背后的原理就是将{}中的内容传递给一个initializer_list,之后initializer_list将元素传递给array,array会判断变量的构造函数能否接受initializer_list这种类型,可以的话直接初始化,不可以的话就将{}中的元素依次取出传递给要初始化的变量
能接受initializer_list就传递initializer_list,接受不了就依次取出进行初始化
Initializer Lists
使用initializer lists可以对变量进行统一初始化,底层使用array
| |
为了实现统一初始化,规定可以使用{},编译器将{}中的内容转化成一个initializer_list<>类型的容器,其中存放初始化的值
相比与variadic templates,这个容器只能存放类型一样的元素,但是元素的个数不定
使用initializer_list初始化时,如果构造函数能接受initializer_list<>就直接调用这个版本的构造函数
如果没有的话需要将initializer_list拆分,拆分出来n个元素,但是没有接收n个元素的构造函数,此时初始化就失败了
底层使用一个迭代器
没有匹配的initializer_list就拆分之后有没有匹配的构造函数
容器可以接受任意数量的参数就是因为构造函数可以接受initializer_list<>,并且有的参数可以接收变长参数也是因为重载了接收initializer_list<>的版本,例如max和min
小总结
c++11提供两种处理变长参数的方式:
- variadic templates:接收的参数不定,类型任意
- initializer_list:接受的参数不定类型一致
explicit
如果使用explicit修饰构造函数,那么编译器就不会隐式的将一些动作转化成对构造函数的调用,只有显式的声明需要调用构造函数时才会调用
c++11之前只有单个参数的非explicit构造函数有时才会提供explicit的修饰,但是c++11之后,一个以上参数的构造函数也可以使用explicit修饰

使用explicit修饰的构造函数只能显式调用
emplace
使用emplace来将元素存入容器中时,容器直接在底层创建对象并将其存入,而不是像push_back一样,先创建一个临时对象,之后使用临时对象接收传入的参数,举例如下:
| |
在底层直接调用Test的构造函数创建一个Test对象,将其存入容器中,即使构造函数有explicit修饰也可以运行,因为这是在底层
显式的调用构造函数,不会发生转换先在局部创建一个临时对象,底层容器收到临时对象之后,创建一个新的对象接收临时对象,调用move函数进行初始化,之后存储这个新的对象,临时对象被销毁
存储的对象与传入的对象之间只是值相同
先在局部创建一个局部对象,之后创建一个新的对象接收这个临时对象,二者只是值相同
range for
范围for循环,可以遍历容器,语法如下:
| |
第一种拷贝方式无法修改元素,第二种引用方式读取到的elem可以修改,并且可以影响到原容器
底层编译器还是使用普通的for循环实现,将容器中的元素依次取出来交给elem
范围for循环和explicit关键字:

原本vs中的string类型的元素可以隐式的调用C的构造函数,从而将string转化成C,但是增加了explicit关键字修饰之后,就无法转换
=default,=delete
如果想让编译器提供默认的构造函数(包括有参和无参),只需要在对应的构造函数后加上一个=default即可,但是如果有自定义的构造函数,就不能使用=default再让编译器给一个默认的,不然会出现二义性
=delete使用的较少,因为不想要可以直接不写,没有必要写出来又告诉编译器我不要
对于同一个函数,=default和=delete不能并存

主要就是使用=default告诉编译器提供一个默认版本的函数
如果只定义了一个空类,编译器会自动地提供一些构造函数和析构函数,这些函数都是inline的,所以在调用这些函数时,会在调用处直接展开,而不是一层一层的递归调用,减少递归的开销
如果想要其他成员不能拷贝自己的内容,就需要将拷贝构造和赋值函数定义为私有,c++11中提供了一个noncopyable类,这个类中的拷贝构造和赋值函数都是私有的,继承这个类就可以不倍拷贝
哪些类需要自定义上述构造函数?

若类中有指针成员,就需要自定义上述几个函数,若没有指针成员,基本上就不需要自定义这些函数
因为指针的拷贝设计到深拷贝和浅拷贝的问题,所以需要自定义这些函数
深拷贝和浅拷贝
简单来说浅拷贝只是对指针的拷贝,拷贝完成之后两个指针指向同一块内存,此时还不会出现问题,一旦调用析构函数,由于存在两个指针,会调用两次析构函数去释放堆区的内存,但是两个指针指向同一块内存,所以会造成同一块内存的二次释放问题
深拷贝就是新创建一个指针,将指针中的值拷贝过来放到新指针中,两个指针除了值一样,指向的内存是不一样的,所以调用析构函数时不会出现问题
Alias Template
化名模板,也就是说给模板一个别名,后期在使用时就可以使用这个别名从而间接使用这个模板,当模板的名称太长时就可以使用简短的别名
但是特化是还是需要使用最初的模板进行特化,不能使用别名
例如:
| |
化名模板并不单单是为了使用模板时少写几个字母
当希望一个函数可以接受不同的参数具有通用性时,第一想法是使用函数模板,接受不同的参数就可以实现通用性,但是对于容器来说,传递不同的容器,想要插入时,还需要使用萃取器得到他能插入什么类型的元素,并不能直接传元素

想要插入元素需要先使用萃取器得到能插入什么元素,才能插入,所以插入元素的步骤很繁琐,并且插入的元素已经固定,不能动态指定
容器->迭代器->迭代器类型->插入元素类型
那么有没有一种模板,接收一个参数,这个参数也是一个模板,并且能够取出这个模板的参数
例如模板接受vector\<string>,而vector\<string>本身也是一个模板,可以取出其中的string,这就是template template parameter
模板模板参数
模板模板参数template template parameter,也就是说,模板中的参数又是模板,例如:
| |
此时就可以直接传递容器名就可以进行测试,并且可以动态的指定容器插入什么元素
不用像上面一样传递一个容器对象,插入的元素已经固定,具体的使用例子如下:
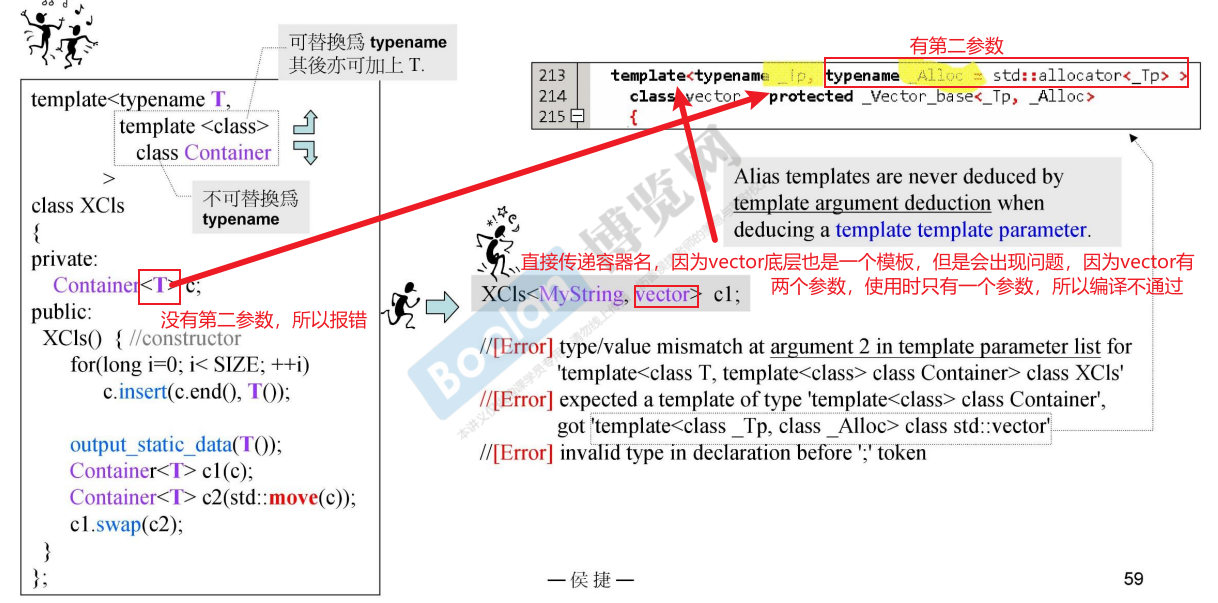
但是直接传递容器名又会出现问题,因为容器有两个参数,我们只希望传递一个模板即可,所以需要使用化名模板alias template来解决这个问题

此时就可以实现不直接传递容器对象,而是传递一个容器名,在函数内部创建容器对象,并且可以动态指定容器插入的元素类型,不用再使用萃取器一层一层获得元素的类型
小总结
化名模板Alias Template可以给模板取一个别名
模板模板参数
template template parameter可以让模板中接收的参数也是一个模板综上,模板模板参数可以接受化名模板作为参数
Type Alias
类似于 typedef,给类型取一个别名,使用using取别名
| |
using
使用using可以定义化名模板alias template、化名类型type alias、命名空间namespace、某个类的某个函数
| |
noexcept
在某一个函数后面加上noexcept关键字,这个函数就不会丢出异常
| |
由于程序的调用是一层一层调用,如果执行foo的过程中出现了异常,会在出现错误这一层尝试处理,如果这一层没有处理这个异常,那么就向上抛出异常,如果上层还没有处理,就继续向上,一直到foo这一层,由于foo增加了noexcept关键字,所以这一层也不会处理
由于foo这一层是最外层,所以再向上就是std::terminate(),会默认调用std::abort(),程序中断
如果类中有move function,就需要使用noexcept关键字修饰这两个函数

override
子类继承父类,重写父类中的方法时,如果方法名后面加上override,编译器就会知道此时是重写父类方法,如果参数列表与父类中的参数列表不一样,那么就会出现错误

对于1来说,本意是重写父类中的方法,但是参数列表写错了,编译器认为这是子类自定义的新方法,不会报错
对于2来说,本意是重写父类中的方法,并且指明override,所以参数列表写错编译器提示错误信息
把继承的本意告诉编译器
final
final可以作用到两个地方:
- 作用到类上,指明这个类是最终的类,不能再被继承了
- 作用到虚函数上,子类继承父类后,父类中使用
final修饰的虚函数不能在子类中被重写
decltype
就像是typeof,可以得到一个表达式的类型,c++中其实也可以用typeof获得一个表达式的类型,但是由于typeof主要在c语言中使用,在c++中并不完整,实现也不完全,所以在c++11新标准中提出了一个decltype来替代typeof
| |
假如知道coll是一个容器,但是忘了他是什么类型的容器,想要使用value_type这个属性时,就可以使用decltype将coll的类型推到出来,从而使用value_type
decltype可以应用在三个地方:
应用在返回值类型中

如上图所示,函数模板中两个不同类型的参数相加,不知道相加之后的返回结果,所以返回值类型不知道怎么写,此时就可以使用
decltype进行推导但是x,y在函数体内定义,编译器会先看到
decltype(x,y),所以不认识x,y会报错,此时需要使用auto进行配合先指定
auto,编译器知道x,y之后,在使用decltype(x,y)推导尾置返回值类型,应用在模板中
模板相互调用之后,对象的类型可能并不是那么明朗,此时可使用
decltype推导出对象的类型
decltype(obj)的结果为T,typename指明后面的部分是一个类型而不是一个函数,1 2 3typedef typename decltype(ob j)::iterator iType //等价于 typedef typename T::iterator iType应用在lambda中
有时候需要使用lambda的类型时,由于lambda的类型太长,所以可以使用decltype来推导出lambda的类型
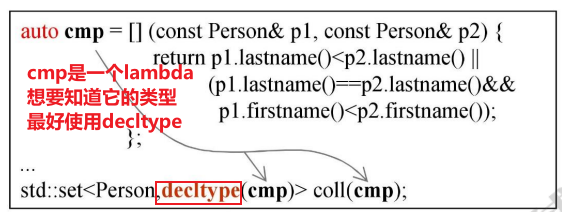
lambdas
类似于内联函数,语法上有所不同,使用lambda可以很方便的声明一个匿名函数(与匿名对象一样),可以将其理解为一个未命名的内联函数
一个lambda表达式的基本语法为:
| |
其中捕获列表可以将lambda范围内的变量进行捕获并在函数体内使用,如果加上mutable就可以对其进行修改,加不加mutable的影响主要是在值捕获的变量上
函数体内想要修改值捕获的变量,就需要使用
mutable,引用捕获(除了const)本身可修改
| |
剩下的就是返回值类型,lambda必须使用尾置返回类型
上面的lambda更简单的形式:
| |
相当于创建了一个匿名对象,使用后即销毁
lambda最简单的形式为:
| |
typename
一旦使用::,前面就需要加上typename
string类型转换
string可以和其他类型进行相互转换,有时我们希望字符串代表的含义是数字,就可以使用类型转换
| |
标准库
右值引用
基础
右值就是只能出现在=右边的值,左值就是可以出现在=号左边的值,也就是左值也可以出现在=右边
可以取地址的就是左值,无法取地址的就是右值
相对的,指向左值的引用就是左值引用,指向右值的引用就是右值引用
但是由于const无法修改指向值,所以const左值引用可以指向右值,这是一种特殊情况
左值引用,使用&修饰
| |
右值引用,使用&&修饰
| |
个人理解右值引用的目的就是为了重新利用地址空间
move
左值引用可以通过加上const修饰指向右值,那么右值有什么方式可以指向左值呢——–>move函数
| |
左值引用一直是一个左值,右值引用作为名称就是左值,作为返回值就是右值
例如std::move(temp)返回值肯定是一个右值,所以std::move(temp)是一个右值,但是ref_a是一个左值
右值引用的应用场景就是避免深拷贝,而是直接移动,将地址偷过来并且避免深浅拷贝的问题
浅拷贝就是防止两个指针指向同一块内存,深拷贝就是新建一块地址将值全部拿过来
上述说的偷在图中表现就是原指针断掉,新指针指向原内存:
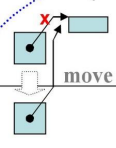
| |
forward
与move类似,forward也可以做类型转换,但是比move的功能更加强大,move只能将左值转化为右值,forward都可以转换,STL标准库中实现了完美的forward转发,那么什么是不完美转发呢?
不完美转发

如上图所示,1调用insert函数传递一个右值,会调用2处的insert函数,因为他接受一个右值,我们最终的想法是可以调用3处的构造函数,因为他也接受一个右值
但是2处将右值接收过来之后变成了左值,因为有一个参数x接收右值,右值有了名字就变成了左值,转发时会转发左值,变成了不完美转发
STL中的forward可以实现完美转发,也就是右值传递的过程中一直都是右值,不会改变类型
对容器的影响
右值引用和普通深拷贝的构造函数,对于不同容器的影响是不同的
- 对vector:右值引用的的速度相比深拷贝更快
- 其他容器影响不大
只要容器中的元素以节点和指针的形式连接起来,那么有没有右值引用版本的构造函数影响不大,如果容器中的元素是连续的地址形式存放,就会有影响
因为vector有右值引用的构造函数时,可以将地址的映射直接拿过来,而不是一个一个的拷贝
总结
上述代码可以实现移动构造函数,不用深拷贝,直接传递右值引用实现深拷贝的效果,并且可以通过move函数的处理接收左值,功能强大
但是转发的过程中由于右值有形参数接收,也就相当于有了名字,右值变成了左值,再转发就变成了左值,造成了不完美转发,解决的办法就是forward完美转发
但是涉及到右值引用的函数体内部一定要有原指针置空的行为,因为他是右值引用,可以改变右值,并且有移动语义,所以可以将原指针置空,相当于浅拷贝+原指针置空 ,之后原指针不能再用
所以在自己定义类并实现移动构造函数时,需要注意将原指针置空,否则会出现浅拷贝的问题,总之要么右值引用要么深拷贝,不能浅拷贝
新增容器
array
是一个不支持动态扩容的数组,定义时指定容量,使用时就和数组一样使用
在普通数组的基础上,增加了一些成员函数和成员变量
array的初始化
| |
HashTable
哈希表,给unordered容器做底层支撑,使用链地址法解决冲突 ,当元素的个数大于数组的个数时就需要扩容,此时 的元素需要再哈希
对于系统内置的类型,可以直接调用哈希函数得到哈希值,但是对于自定义数据类型,系统不知道如何哈希,所以需要自定义哈希函数
自定义类型有了哈希函数之后( 四种方式 ),对应的容器就可以使用这个哈希函数存放自定义类型
只需要将哈希函数作为参数传递过去即可
总结
将c++11/14中的新特性列举了出来,并不全面,但是可以供后期复习使用